Development Tools:
The project was done using Python and Jupyter Notebook. Some libraries include, but are not limited to:
Project-related information:
For in-depth information on the complete project, click the "Visit" button above.
This is a project where I had to implement my own code that performs nested cross-validation and the k-nearest neighbour ML algorithm, build confusion matrices, and estimate distances between data samples.
The purpose of this project was to help me:
- Get familiar with common Python modules/functions used for ML in Python
- Get practical experience implementing ML methods in Python
- Get practical experience regarding parameter selection for ML methods
- Get practical experience in evaluating ML methods and applying cross-validation
The K Nearest Neighbor algorithm is a supervised machine learning algorithm that relies on labelled input data to a function that assigns the appropriate label to new unlabelled data.
There are a couple of basic steps that need to be taken into account in order for the algorithm to work and these are:
- Calculate the distance between the unlabelled data and the labelled data. (Euclidean Distance in my implementation)
- Add the distance to an ordered collection.
- Sort the data.
- Pick the first K entries from the ordered collection.
- Get the labels for the selected points.
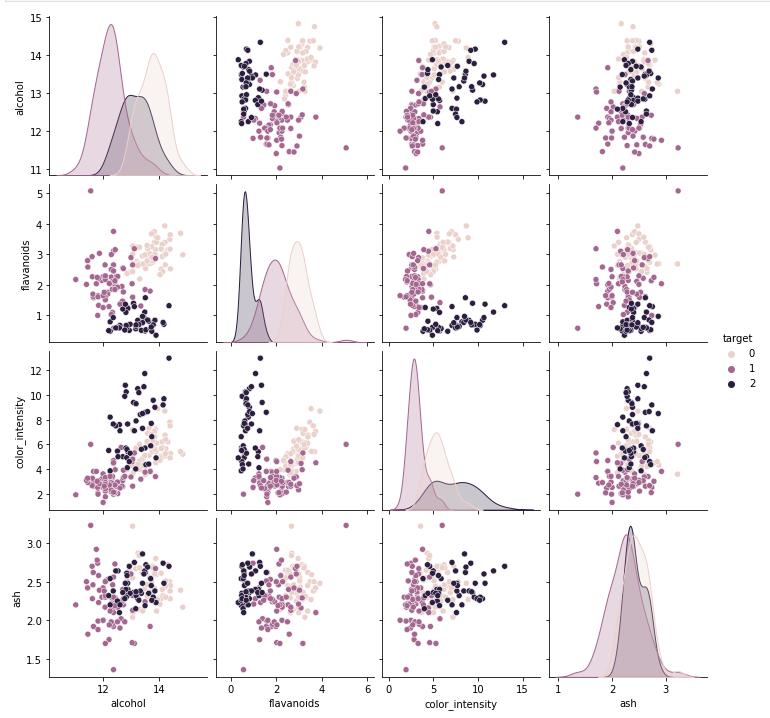
Below is a screenshot of the grid plot with the different properties of the wine dataset that was used in the project.